Build a GraphQL Gateway: Combine, Stitch or Merge any Datasource

In this article, we’ll discuss the problem of how to fetch data from multiple sources while still keeping our frontend snappy, and a potential solution: using a GraphQL Gateway.
As software engineers, we’ve all faced the challenge of combining data from many systems. Even a single page requires data from several services to render.
Data is everywhere, from CRMs to financial systems and SaaS platforms to databases. Every business inevitably buys a plethora of SaaS platforms, then wants a unified business view on top of all of them. We have to embrace this head on and integrate everything.
A GraphQL gateway combines the benefits of a traditional API gateway with GraphQL.
We’ll start by discussing the benefits of an API gateway, and then look at how GraphQL fits in. Stick around to the end of the article, where we look at some frameworks for building our own API gateway.
Benefits of an API Gateway
Securing our public-facing APIs against hackers is a full-time job. Over time, organizations have evolved to create many APIs, from SOA to microservices. Instead of putting these APIs directly onto the Internet, organizations prefer to add an extra layer of security that sits in front of all these APIs and ensures that access to data always follows the same authentication rules.
They do this with an API gateway.
Products such as Kong or Apigee expose internal APIs from a central location. They act as a reverse proxy with features like API key management, rate limiting, and monitoring.
The API gateway allows us to control who and what has access to each service, monitoring the connections and logging access.
More recently, apps have been required to combine data from an API gateway and other external SaaS providers. This means that the old centralized tool — which ensured our rules were followed — is now bypassed on a regular basis.
Imagine we’re building a web app for our company. We have a task to create the user profile page. During the login process, we need to combine data from many systems:
- Salesforce CRM: holds the general customer data such as first and last name.
- Orders: recent orders are in an ordering system within the organization.
- Notifications Service: the notification settings and recent messages are in an app-specific database connected to a Node.js service.
The client would need to make three separate requests to get the data, as represented in the image below.
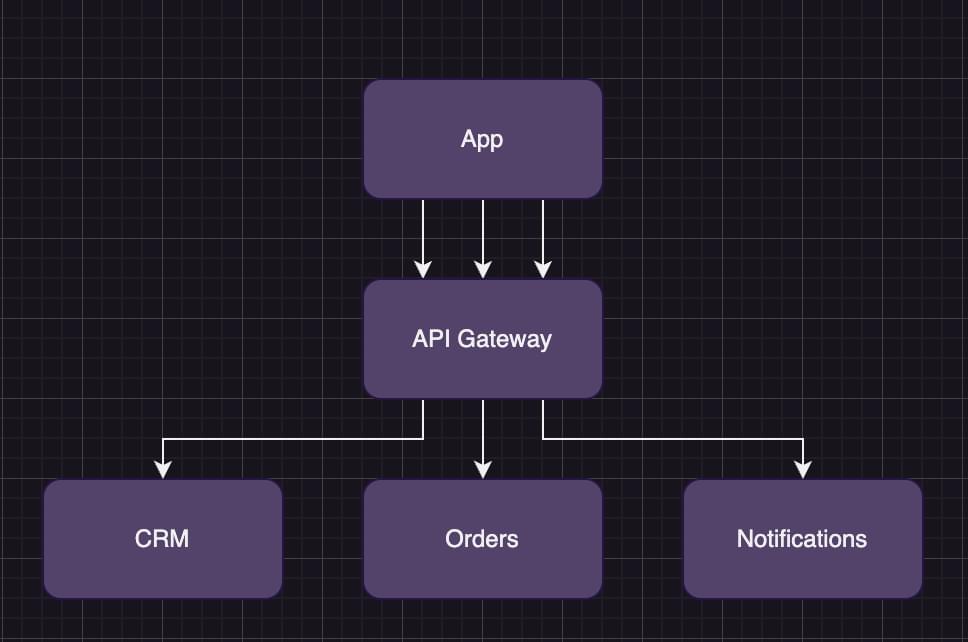
In the image above, the web client sends three separate API requests and then has to combine the results in frontend code. Sending multiple requests affects the app’s performance, and combining this data increases the complexity of the code. In addition, if there’s more than one app, now all apps have to be aware of all backends, and a single API change in one service can result in updates to all of our applications.
We can do better. Ideally, we want to reduce the requests from three to a single fetch. We could create a new service to do that — a service that orchestrates requests to backend services. This idea has a name: the BFF pattern.
The Backend-for-frontend (BFF) architecture pattern allows a single request from the frontend.
But how does it work? Let’s look at this pattern in more detail.
The Benefits of the BFF Pattern
With the BFF pattern, an application sends a single request to the API gateway. The BFF service then requests data from each backend service and combines it. Finally, the data is filtered, returning only the data needed for the front end, reducing the data sent over the wire.
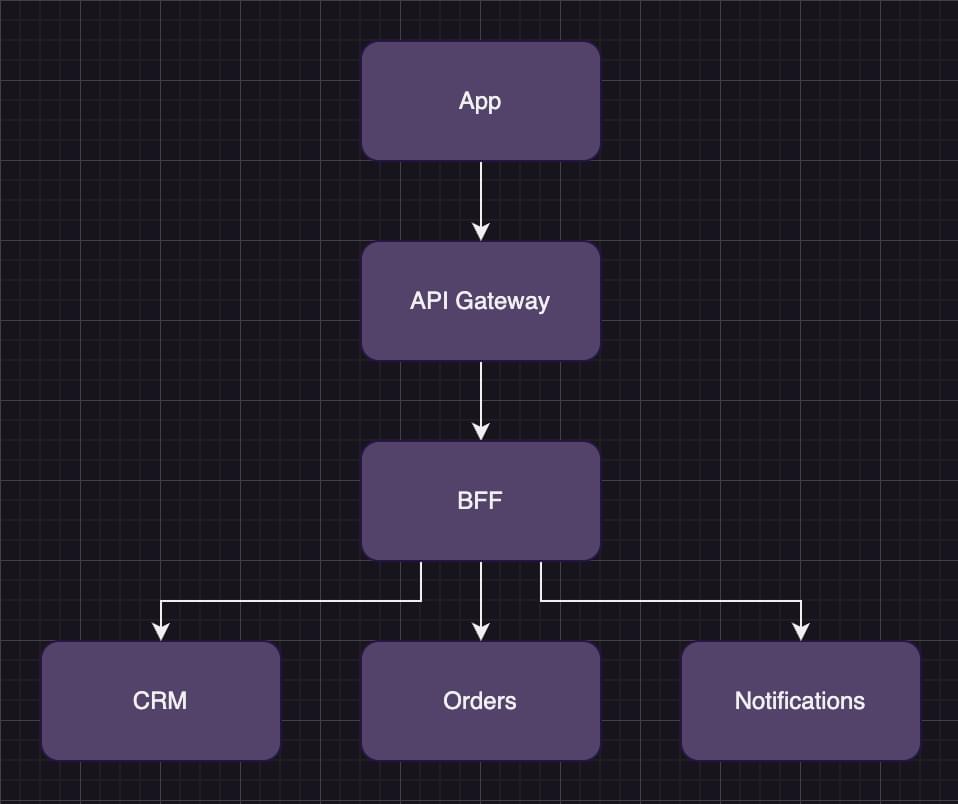
As illustrated in the image above, we’ve introduced an extra layer into the stack to orchestrate the request.
The user profile endpoint returns the data needed for that app on the profile page. Reducing our three requests to a single request has fixed our previous performance issue.
But we aren’t finished yet.
The business has decided to release a mobile app. The mobile app also has a profile page, but this screen displays much less profile information.
At this point, the mobile team has two options. The team could reuse the web team’s endpoint, which would mean we over-fetch the data (fetching more data than is needed for the mobile app). The alternative is that the mobile team creates their own BFF.
Not surprisingly, the mobile team decide to create their own BFF, as they want good performance for their app.
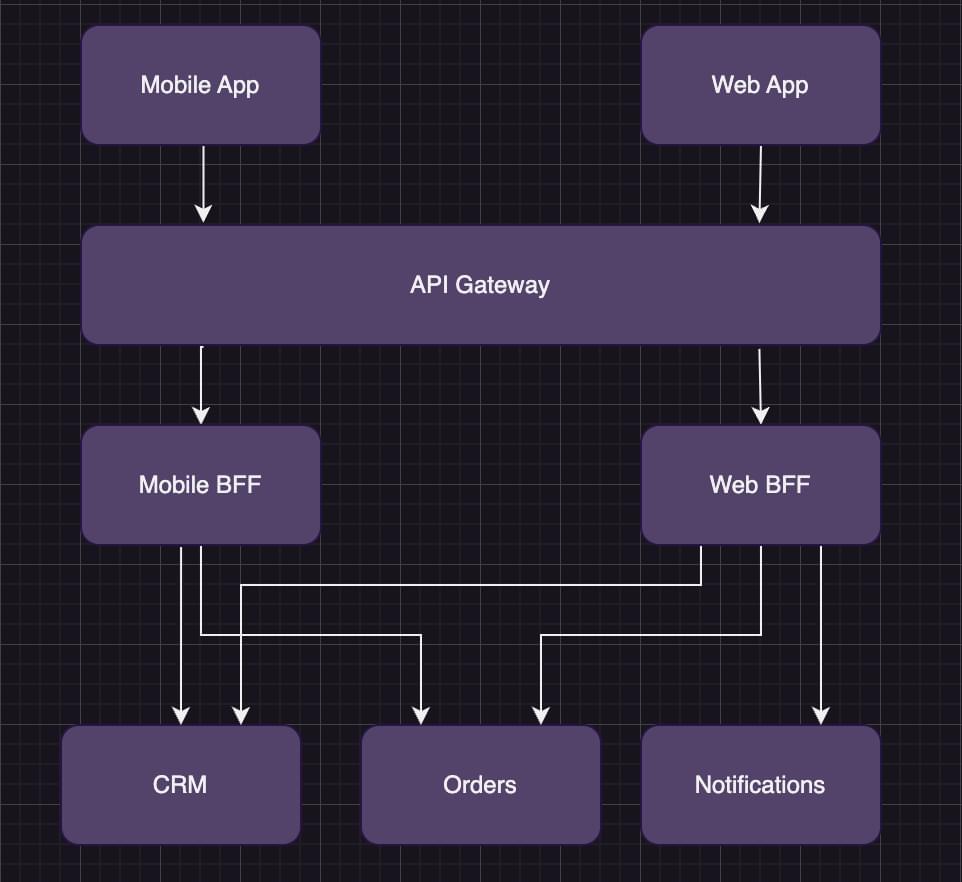
As illustrated in the image above, things are starting to get complicated, and we now have two new issues:
- Each team has to create a new BFF service for each application they create, slowing each team down and making it hard to standardize.
- Each BFF needs to be pen-tested to ensure it’s secure.
How do we solve these issues?
We need a solution where each app can select the data it needs, and it should be a single API used by all applications in the company.
As BFFs have matured, many developers have started experimenting with GraphQL instead of REST.
Let’s look at how this technology can help.
The Benefits of GraphQL for a BFF
GraphQL has many strengths that make it an ideal technology for a BFF:
- Efficient Data Fetching. GraphQL enables clients to request exactly the data they need and nothing more. This improves performance by reducing the data that’s transferred from the API.
- Single Endpoint. Instead of exposing many endpoints via the gateway, GraphQL uses a single endpoint for all requests. This simplifies the maintenance and the need to version.
- Flexible queries. Clients can construct queries by combining fields and relationships into a single request. This empowers frontend developers to optimize data fetching, increasing performance. In addition, if the requirements for the frontend change, it can be updated to fetch different data without altering the backend in any way.
Frontends can now select only the data they need for each request.
We can now connect both our apps to the same GraphQL server, reducing the need for a second BFF service.
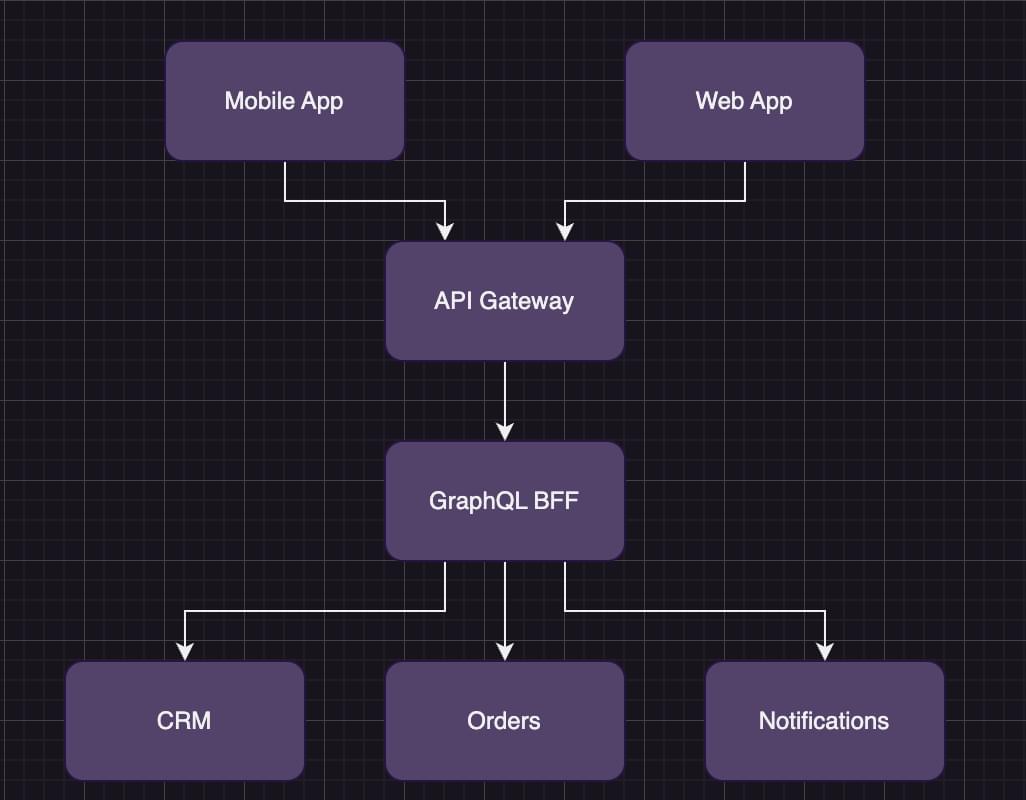
We can now share the BFF for any app in the organization. We also have a single endpoint that needs to be pen-tested.
But again, we’ve introduced a new problem! We still have to manage two systems — the API gateway and the GraphQL BFF.
What if we combined the two into a GraphQL gateway?
Next, let’s look at how a GraphQL gateway works.
What is a GraphQL Gateway?
A GraphQL gateway combines an API gateway with a GraphQL API to get the best of both technologies.
Let’s recap the benefits:
- Developers have a single API endpoint to request data from. This reduces over- or under-fetching, as each application selects only the data it needs.
- The GraphQL gateway is shared by many apps within the organization. This means we have reduced our security exposure to a single API endpoint.
- We only have a single service to manage, now that the BFF is combined with the gateway.
The diagram below shows how the user profile API request works with a GraphQL gateway.
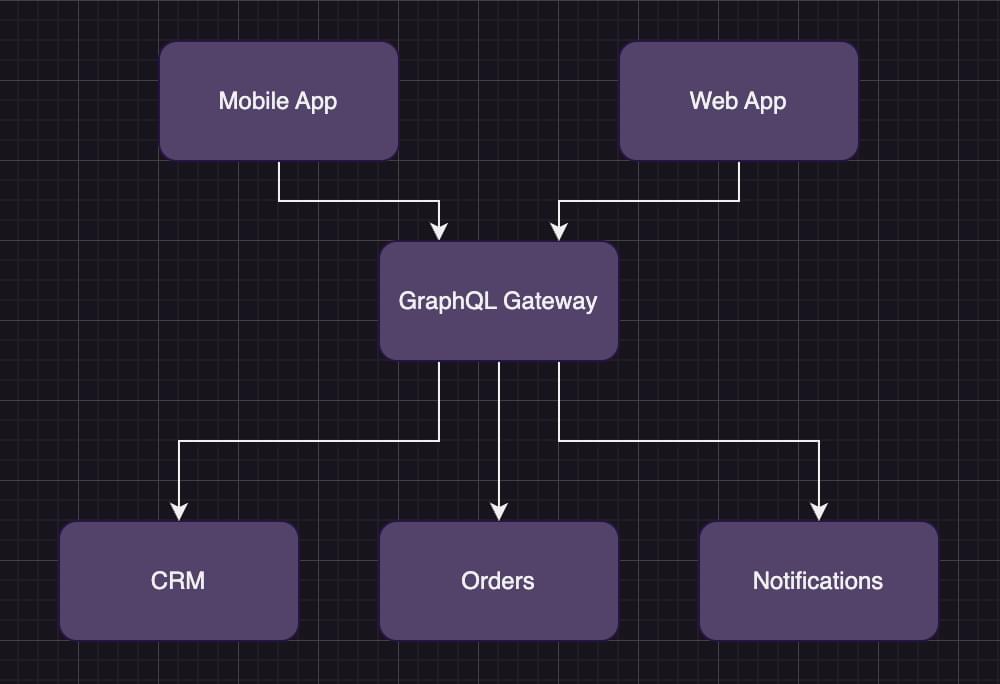
In the image above, the client sends a single request to the GraphQL gateway, requesting the data it needs. The gateway makes individual requests to each service and combines the results. We now only have a single service to manage and deploy.
Hopefully, you’re ready to try this for yourself. Next, let’s look at how we can build a GraphQL gateway.
Building a GraphQL Gateway
When choosing a gateway framework, we want to look for some key features:
- Multiple Sources. The gateway must connect to many data sources — from databases to SaaS — and we should be able to create our connections.
- Routing. The gateway should be able to request data from the underlying services directly.
- Batching. Multiple queries to the same service are sent in a batch, reducing the number of requests.
- Security. Authentication and authorization should control who can access the connected data.
- Cross Datasource Filtering. Powerful filters should be available to not over-fetch the data needed by the client.
- Extensible. Developers should be able to extend the code with middleware or functions to fit their needs.
There are many frameworks to choose from, but here are the top three that I recommend exploring further.
Hasura
Hasura has gained popularity over the years, initially as a GraphQL-over-Postgres server. However, it has added the ability to connect to external systems.
We can connect a “Remote Schema”, which combines GraphQL from other servers.
There are some downsides to this approach. The first is that we need to create and manage our remote schema in a separate service, and this service must be a GraphQL endpoint. This leads to the second issue: we can’t connect the data source directly.
In addition, Hasura doesn’t allow us to filter data in one data source based on the values in another. This might sound academic, but it’s actually pretty common that we want to express something like, “Give me orders where the customer name is ‘ABC’.”
This offers flexibility, but at the expense of running multiple services. Let’s look at an option that will connect directly.
StepZen
StepZen allows us to connect to the data source directly from the GraphQL server. This reduces the need to run multiple services to create a gateway.
To connect Stepzen to a data source, we create a GraphQL schema file like this:
type Query {
anything(message: String): JSON
@rest (
endpoint: "https://httpbin.org/anything"
method: POST
headers: [
{name: "User-Agent", value: "StepZen"}
{name: "X-Api-Key", value: "12345"}
]
postbody: """
{
"user": {
"id": "1000",
"name": "The User"
}
}
"""
)
}
In this example, we’re connecting the server to a database using the custom schema.
There’s another option that you may prefer, and that is a code-only approach. Let’s look at that next.
Graphweaver
For the past few years, I’ve been working on an open-source product called Graphweaver, which can be used as a GraphQL gateway.
It connects directly to our data sources and creates an instant GraphQL API. This API includes all the CRUD operations we might expect to create, read, update, and delete. It auto-generates filters, sorting, and pagination arguments, saving time. We can extend the built-in operations with our code for complete flexibility.
Graphweaver has out-of-the-box data connectors for databases such as Postgres and Mysql and SaaS providers like Xero and Contentful.
Making changes or connecting data sources involves writing Typescript code, giving us complete customization.
If you’re interested in creating your own GraphQL API, I highly recommend you take a look at the Graphweaver GitHub code.
Conclusion
In this article, we’ve looked at how to replace our current API gateway and BFF pattern with a single GraphQL gateway.
We’ve looked at the benefits of an API gateway and why organizations use them. Version control, rate limiting and access management are some of the reasons.
We also looked at the BFF pattern and how it orchestrates API requests for frontend apps.
Finally, we looked at GraphQL and how this is a beneficial technology for BFFs.
Ultimately, this led us to creating a GraphQL gateway, and we looked at three options for creating our own: Hasura, StepZen, and the product I’ve been working on, Graphweaver.
I hope this article has convinced you to try a GraphQL gateway of your own, and if so, that you’ll consider giving Graphweaver a try.