Multimodal ChatGPT: Working with Voice, Vision, and Images

In this article, we’ll take a look at the new multimodal capabilities of ChatGPT: how they work, and how they might be used by creators.
Since the public release of ChatGPT in late 2022, creators have been continuously adopting the AI for tasks ranging from brainstorming ideas and summarizing text to generating scripts, copy, and even code.
Building on this momentum, OpenAI has rolled out an update to ChatGPT, expanding its skill set to include not only text-based responses but also visual and auditory interactions.
A New Era of Interaction: Voice and Vision Capabilities in ChatGPT
Harnessing AI for content creation is nothing new, and there’s no shortage of AI text generators on the market in 2023, each of them trying to outdo each other with the latest features and functions. But it appears that OpenAI is staying one step ahead of the pack with this latest announcement.
While OpenAI are rolling out these features slowly, they’ll soon be available for all GPT Plus users. Let’s take a closer look at these new features.
Synthetic Speech
ChatGPT has recently expanded its capabilities to include text-to-voice, and voice-to-text functionalities.
Users can now engage in real-time voice conversations with ChatGPT, and the feature is powered by a new text-to-speech model that generates human-like audio. Voice interaction is available on iOS and Android platforms and offers users the choice between five different synthetic voices.
The technology also employs OpenAI’s Whisper speech recognition system to transcribe spoken words into text, enabling a seamless back-and-forth dialogue. Voice functionalities are being gradually rolled out to Plus and Enterprise users at the time of writing.
Computer Vision
ChatGPT now incorporates vision capabilities, allowing users to upload and discuss images within the chat interface.
The image understanding is powered by multimodal GPT-3.5 and GPT-4 models, which apply computer vision and language reasoning skills to various types of images, including photos, screenshots, and documents containing both text and images. One X user already used the features to solve a sheet of basic math problems.
Users will be able to interact with these features on all platforms and even use a drawing tool on the mobile app to focus the assistant’s attention on specific parts of an image. According to OpenAI, this new functionality is designed to assist users in daily tasks, such as troubleshooting appliance issues or planning meals based on the contents of their fridge.
OpenAI have also announced their latest text-to-image tool Dall-E 3, which will now be integrated into ChatGPT opening up a range of additional functionality. Notice the text “Super-Duper Sunflower” in the bottom right image below – another new feature not seen before.
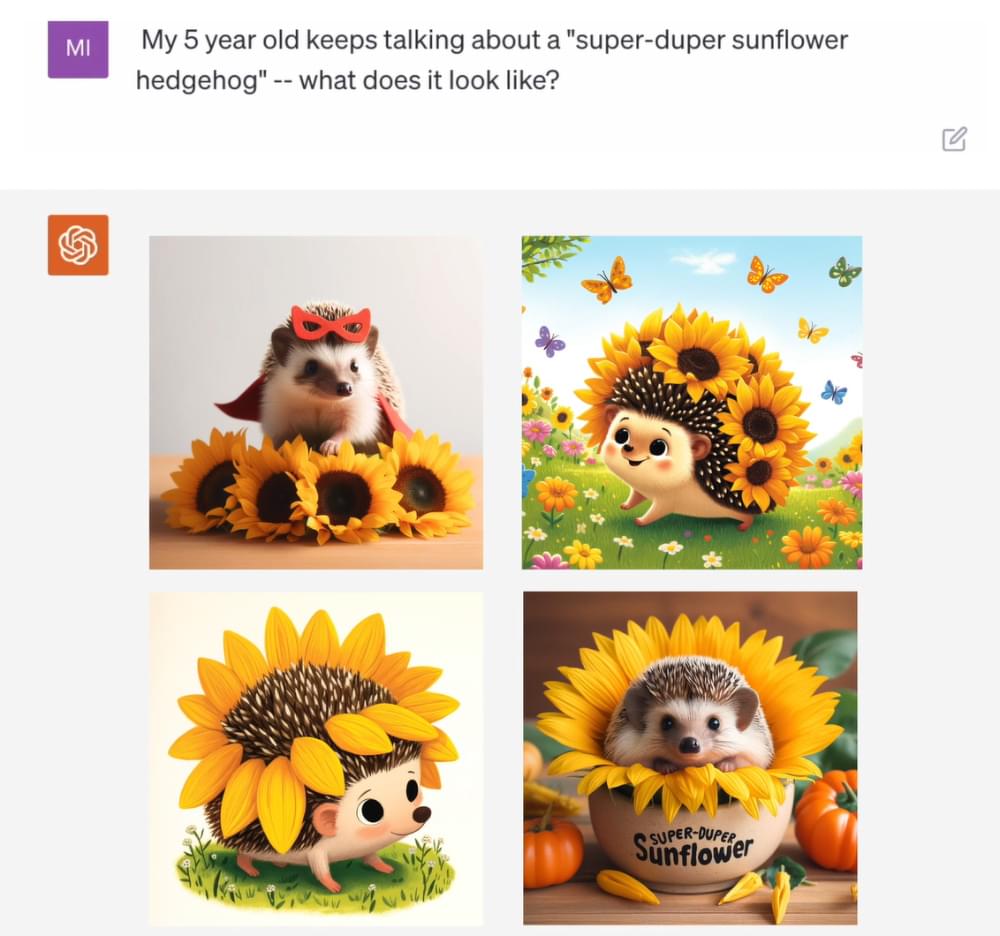
Image credit: OpenAI
Multimodal ChatGPT Use Cases in Content Creation
While it’s still early days, as these features roll out, we can expect creators to find many weird and wonderful ways to use multimodal GPT in their workflows. Let’s take a look at some of the obvious applications we can expect to see right away.
1. Interactive podcasts
One neat application is interactive podcasts, where a ChatGPT voice assistant could serve as a virtual guest speaker and respond in real time to conversations with the hosts. As ChatGPT improves it could also do real time fact checking and assist in guiding conversations. This will likely be one of the early use cases that will be interesting to watch unfold.
2. Voice-powered writing assistant
ChatGPT’s natural language abilities also lend themselves well to voice assistants that can help content creators with research and writing. A voice-powered ChatGPT could summarize articles or studies, pull key data points, or draft sections of written content after being given an overview. It’s effectively transforming AI conversations in the same way that audiobooks reinvented the way we read novels.
3. Audio descriptions and alt text
ChatGPT also holds promise for generating audio descriptions of visual content like videos, charts, or infographics. Automated image captioning is another great use case. ChatGPT could scan an image and generate SEO-friendly captions or alt text describing the visual elements present. ChatGPT’s natural language skills make it well-suited to crafting highly descriptive captions, which would normally take quite a bit of time for the human operator.
4. Transcription and idea organization
Another great application for ChatGPT’s voice tools is by using the AI to transcribe conversations and organize ideas. ChatGPT can now actively listen to a conversation and provide real-time transcription, organization, suggestions, and summaries. This functionality would enable quick summarization of brainstorm sessions between creators and could even suggest new ideas based on their conversations.
5. Visual enhancements
ChatGPT’s computer vision capabilities open up new possibilities for enhancing visual content and experiences. One application is using ChatGPT to analyze article drafts and suggest types of visuals that would strengthen the content, like data visualizations, photos, illustrations or infographics. This allows writers to easily identify gaps where a chart, graph or image could improve clarity and engagement. The integration of Dall-E 3 could even help generate these images.
6. Image-based answering
ChatGPT also shows promise for image-based question answering, where users upload an image to receive tailored responses based on visual analysis. This has useful applications across sectors like retail, home improvement, or medical fields. One early example demonstrated ChatGPT providing an in-depth description of a human cell based on nothing but an image.
7. Image-based code
Using its new computer vision skills, ChatGPT can now analyze an image of a web page and output the corresponding HTML code. An X user has already leveraged this feature to quickly turn a screenshot of an existing SaaS dashboard into working code. This image-to-code functionality is a powerful tool that creators will apply to landing pages, ecommerce sites, and various other web projects.
8. Interactive multimedia
The combination of ChatGPT’s new voice and vision features has some exciting possibilities when it comes to multimedia and interactive content. One application is using ChatGPT to generate narrated, interactive stories or entertainment programming with a mixture of text, images, and voiceover automatically stitched together. There’s even potential for video games to be created right there in ChatGPT.
For educational content, ChatGPT could guide students through interactive learning modules with a blend of on-screen text, voiced explanations of concepts, and relevant imagery surfaced by the AI.
Customer service is another area that could benefit. An AI assistant could interpret customer queries from either text or voice input, while also analyzing any photos or videos shared of issues. The AI could then respond with a combination of generated speech, text, and visuals tailored to the specifics of each customer’s case.
Wrapping Up
To sum up, OpenAI’s multimodal upgrade serves to give users and creators a giant leap in functionality.
Whether you’re a content creator interested in new avenues for brainstorming or storytelling, or a professional searching for efficient task automation, these updates offer massive potential.
As these features become more widely available, they’re likely to significantly broaden how we interact with and leverage AI in our daily tasks and creative endeavors.